T-SQL 101: 51 Splitting delimited strings in SQL Server by using STRING_SPLIT
For a long, long time, users of SQL Server had requested some way to split a string. That’s a common need when working with rows from comma-delimited files (CSVs).
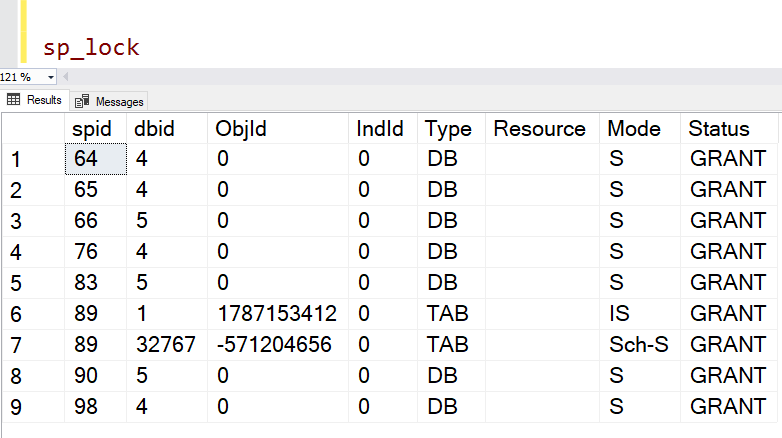
In the example below, I’ve asked it to break up the string ‘Greg,Tom’,Sandra’ whenever it finds a comma. Notice I could use another delimiter like TAB or semicolon instead.

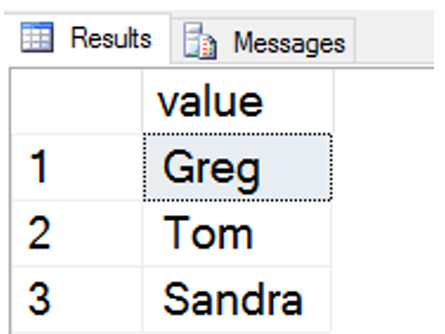
The values returned are in a table. This is a table-valued function.
2020-01-06