

SDU Tools: List use of Deprecated Data Types in a SQL Server Database -> Updated
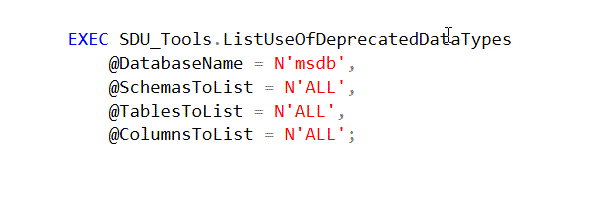
I’ve previously posted about the procedure ListUseOfDeprecatedDataTypes in our free SDU Tools for developers and DBAs. I mentioned that I’m often reviewing existing databases and one of the first things I go looking for is the way they’ve used data types, and that in particular, I’m keen to know if they’ve used any deprecated data types (i.e. ones that will/might be removed at some point).
The procedure was updated in version 21 to now include a ChangeScript column. (Thanks to Michael Miller for the suggestion).
2023-06-02






