
SQL: Implementing Optimistic Concurrency in SQL Server with RowVersion

It’s common to need to have a way to read a row of data from a table, to be able to modify it, and to then update it back into the table, but only if it hasn’t been changed in the meantime. But we don’t want to lock it in the meantime. That’s the basis of optimistic concurrency. By contrast, pessimistic concurrency would hold locks the whole time. In SQL Server, you should use the rowversion data type to implement optimistic concurrency.
Early versions of SQL Server and Sybase had a timestamp data type. That was a really poorly named data type because it had nothing to do with time. It was an incrementing binary value that could be used to implement optimistic concurrency. Since SQL Server 2005, it has been renamed to the rowversion data type. That’s good because it more accurately describes what it actually is.
Let’s take a look:
First I’ll create a table that uses a column that has a rowversion data type.
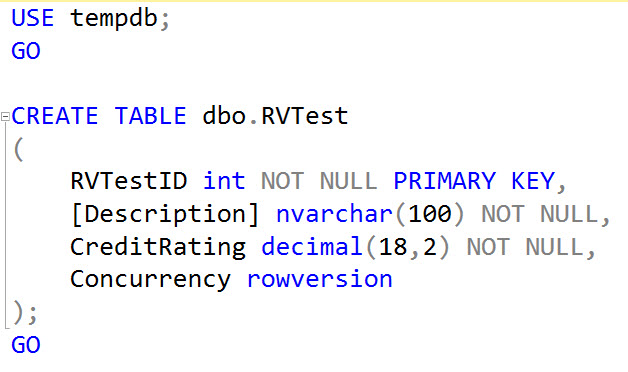
I’ve called the column Concurrency but it could be called any standard column name. It would be good though, if you named these columns consistently across your tables where you use them. Now let’s insert some data.

Note that I didn’t include the Concurrency column in my INSERT statement. You can’t insert directly into that column. Let’s see what got stored.
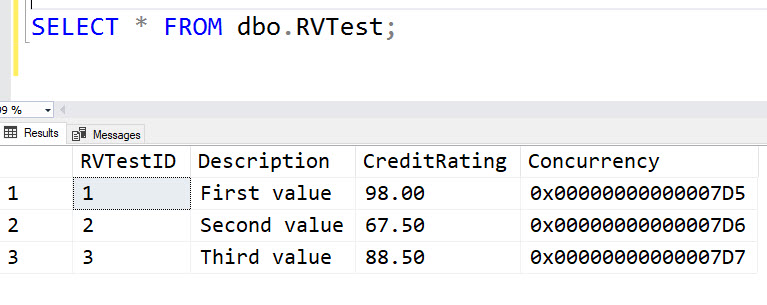
You can see that a different value was stored in each row. The values are actually quite predictable and the binary value just keeps increasing. Now let’s look what happens when we update a row.
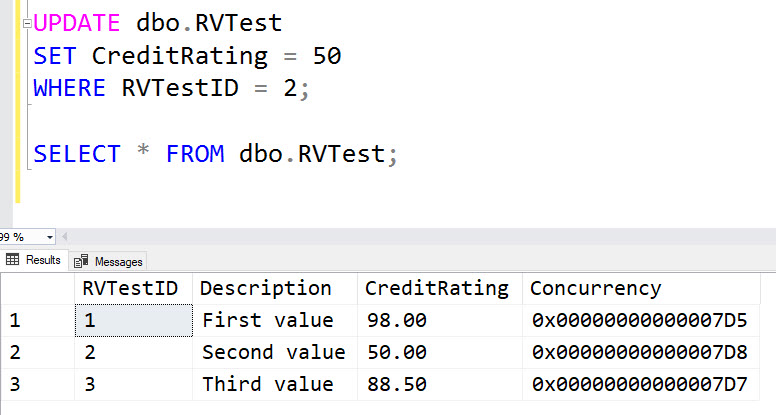
The value in the updated row has increased. Any time the row is modified, the value changes. But what if you make a change but leave the value the same?
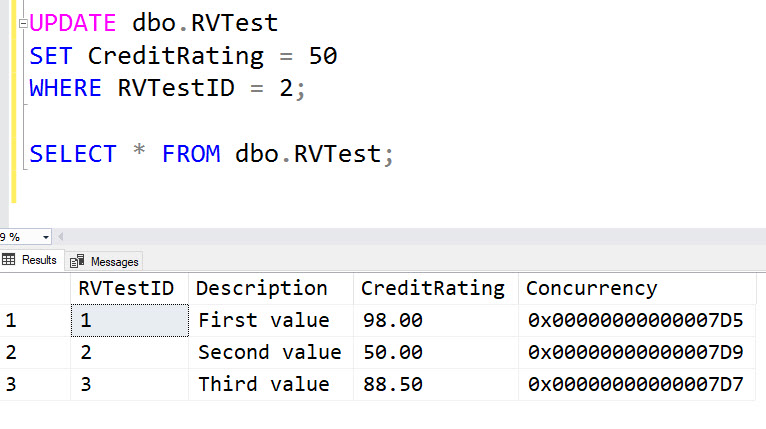
Notice that the value changed again. So the issue isn’t whether or not any column value changed; it’s just whether or not an update was performed on the row.
This is perfect for an optimistic concurrency system. All I need to do is to read the value of the Concurrency column when I read other columns from the table, and when I update the row, I include a WHERE clause that checks the value is still the same. Then if no rows are matched for my UPDATE, I know that someone else modified the row in the meantime.
Having this support in the back end of the database avoids all the potential race conditions that might come from trying to implement this in code yourself.
As an interesting note, the last value used for the rowversion column is calculated at the database level, not the table level. If I create another table, the same set of values will just continue on. At times, we’ve used these to find all changes in a database. You can find the last value for a database by reading the @@DBTS system variable.
2018-09-24