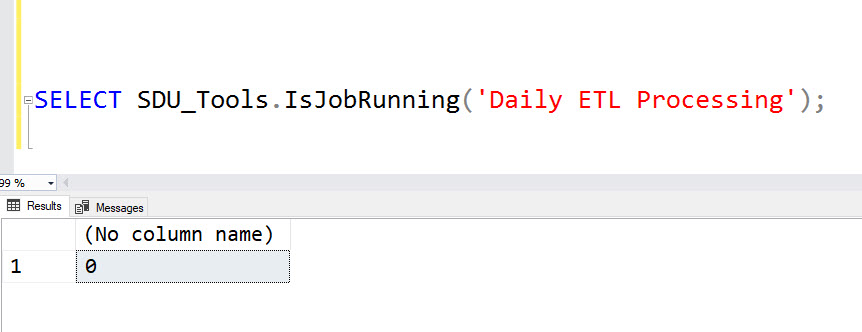
SDU Tools: Is XACT_ABORT on in my SQL Server session?
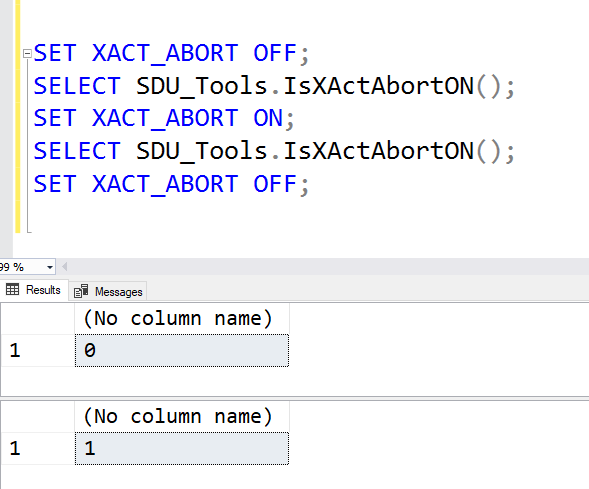
XACT_ABORT is one of the least well understood options that you can configure in a SQL Server session. Yet it’s very important. XACT_ABORT makes statement-terminating errors become batch-terminating errors. Without it, even within a transaction, many errors only terminate the statement that they occur in, and control passes to the next statement within the transaction, not out of the transaction.
In nearly every stored procedure that I write, the template includes the following lines:
2018-10-10