
T-SQL 101: 15 Using column and table aliases in SQL Server queries
Look carefully at the following queries:

I’ve shown several examples here of what are called aliases. There are two basic types of aliases.
Column Alias
In the first query, I’ve used a column alias. I wanted to query the Description column in the dbo.Products table but I wanted the column called ProductName instead. So I follow the column with the word AS and then the name I want to use for the alias.
2019-04-29


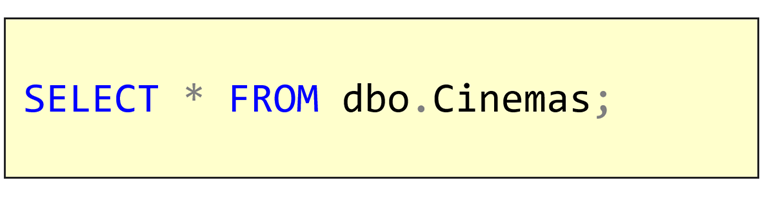
 Image by Ken Treloar[/caption]
Image by Ken Treloar[/caption] Awesome image by Jens Johnsson[/caption]
Awesome image by Jens Johnsson[/caption]