Power BI: AddWeekdays function for Power Query M language
In our free SDU Tools for Developers and DBAs was an AddWeekdays function. Now that was for T-SQL. Recently though, I needed to do that for Power Query. While the M language has a wonderful set of date-related functions, it didn’t have this one.
That made it time to write one. Here’s the code that’s required:
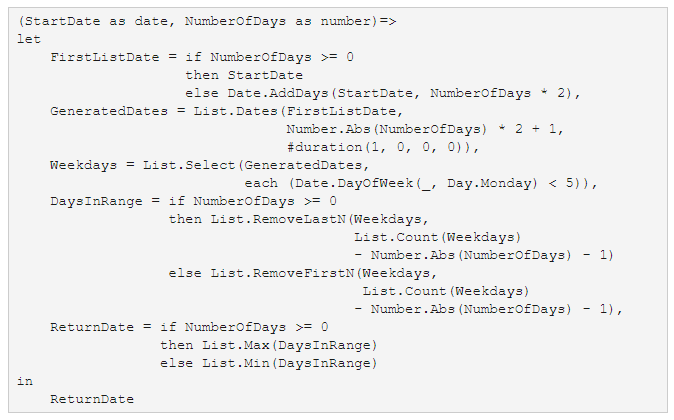
So how does it work?
Forgive the formatting to fit this window, but let’s take a quick look through it:
2019-04-09