
SDU Tools: List Mismatched Data Types

I might be somewhat anal when it comes to database design. (Probably almost any type of coding). Perhaps it’s a mild form of OCPD-behavior , but inconsistency frustrates me. (I’m told that OCPD is the correct term, and that people often apply OCD to that behavior incorrectly).
Worse, inconsistency leads to nasty, hard-to-find errors and your applications become more and more fragile.
If I’m holding an email address and I define it as 70 characters in one place, 100 in another, and 160 in yet another, I have the chance of random failures when I’m moving data around or assigning values from place to place. (For email addresses, I recently discussed why they should be 255 characters anyway).
Same for an address, or phone number, but even more insidious if I use different precision in decimal values ie: 2 decimal places here, 4 over there, 3 in other places. Then, random rounding issues can occur.
No matter how hard organizations try, database designs routinely end up inconsistent.

How do you find it? We have a tool to help !
One of the SDU Tools is used to find all columns that have the same name, but are defined differently in different parts of the same database. You might get some false positives, but if you haven’t run something like this on a database before, you might be surprised by what turns up.
The main parameter is the database name, but you can optionally limit it to one or more schemas (you can provide a comma-delimited list), one or more tables, and/or one or more columns.
Here’s an example run against the WideWorldImporters sample database that we created for Microsoft:
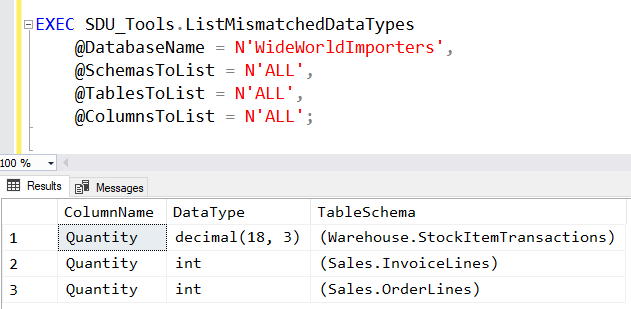
In this case, the difference was intentional, but it’s important to see the differences and to decide if they are appropriate.
You can see it in action here:

You can find out more about our free SDU Tools here:
https://sqldownunder.com/freestuff
2017-11-29