
SQL: Filtered indexes in SQL Server can be wonderful but be careful !

Back to the transaction table
Two weeks ago, I wrote about the issues with a large transaction table where only a handful of the rows were unfinalized, and that we would never use an index to find all the rows that were finalized. But we’d certainly want an index defined for the ones that weren’t. If you haven’t read that post, I’d suggest you do so before continuing to read. You’ll find it here.
Now one of the challenges is that indexes like this on a very big table, can also be large. Also, every row in the table has an entry in each index.
Why filtered indexes?
If you think about it, if all we’re ever going to use is one part of the index, i.e. just the unfinalized rows, having an entry in there for every single row is quite wasteful, as although the vast majority of the index will never be used, it still has to be maintained.
So in SQL Server 2008, we got the ability to create a filtered index. Now these were actually added to support sparse columns. But on their own, they’re incredibly useful anyway.
The idea is that we can have a WHERE clause on the index and the index only contains entries for the rows that match the WHERE clause predicate. These indexes are often much smaller and can also be much faster, but it’s really important that you’re very, very careful when using them.
In particular, you normally need to include the predicates when you use them in queries. Let me show you why.
Quick demo
Here in my Indexing database, I’m going to create a table called Transactions.
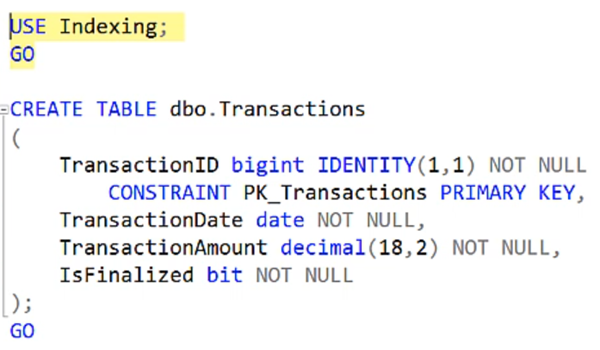
I’ve got a TransactionID as just an identity column, a date, an amount, and IsFinalized. So now I’ll populate it. I’m going to just add 100 thousand rows.
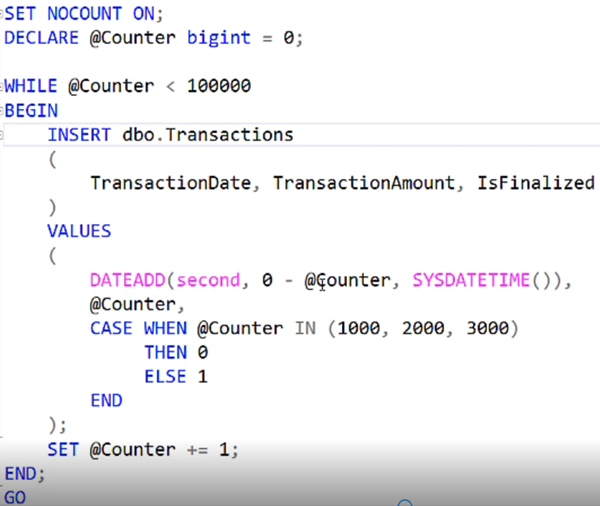
But what I also did was to have it calculate the transaction date on the fly and I’ve got three rows where I’m going to set the fact that the transaction was unfinalized. All the other ones have it set as finalized.
What I’m going to do is create a normal index on that IsFinalized column.

Keep in mind that what that index will contain is the IsFinalized column, along with the clustering key which was TransactionID.
Now let’s look at some query plans. Here are the queries:

Here are the query plans:
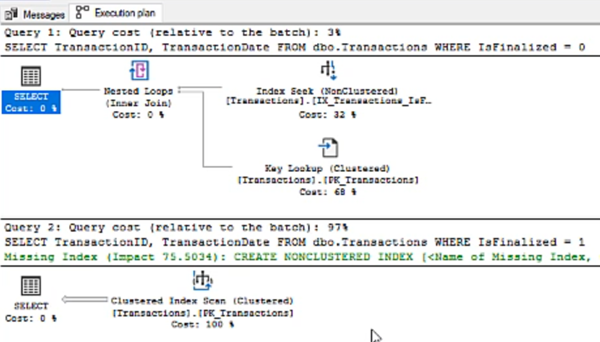
No huge surprise there. Note that it wasn’t a brilliant index, because a lookup was needed to get the date. But the first one decided that the statistics were OK for a series of lookups, so it does that. The second one just complains there is no suitable index.
Now let’s try a filtered index instead:

And we see that they’re basically the same:
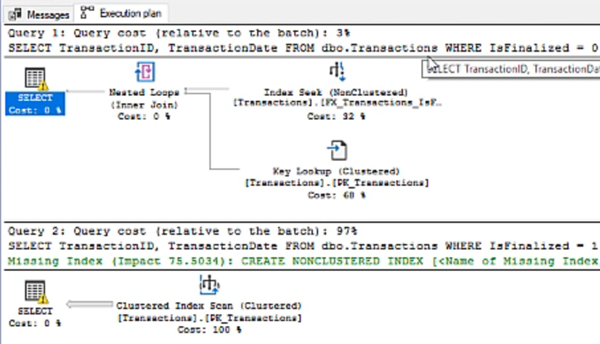
The difference is that it’s picked up the filtered index in the first query. But it could only do that because it matched the predicate entirely, and was able to do so before it ran the query.
Parameter problems
Instead, if I declare a variable, and I use it in the predicate, it’s the same logical query, but the outcome is entirely different. Here are the queries that use variables:

And here are the query plans:
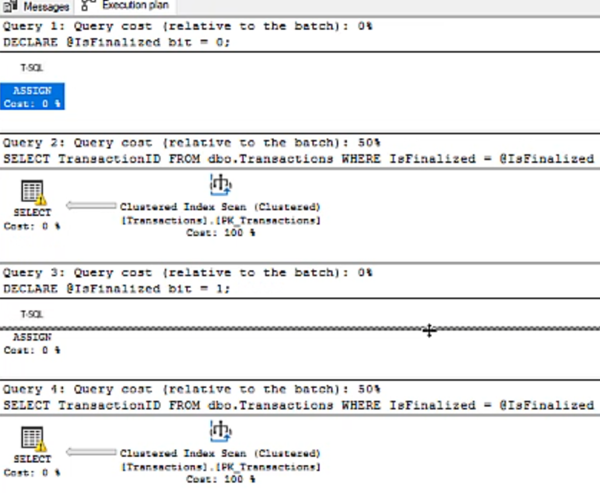
Yep, now they’re both broken. That’s because at the time the query plan was created, SQL Server didn’t know what value that variable would have. (In this case, you’d think it could work that out actually but it doesn’t). And so it doesn’t know if the value will match the filter predicate, so it also doesn’t know if it can use that filtered index, so it doesn’t.
The main thing is that if you use a filtered index, although they can be absolutely wonderful, it’s really, really important that you match the filter predicates exactly, even if you also have other predicates in the query.
Learn about indexing
Want to learn more about indexing? Take our online on-demand course now: https://sqldownunder.com/courses/idx
2019-01-14