Machine Learning: Testing your installation of R and Python in SQL Server 2017
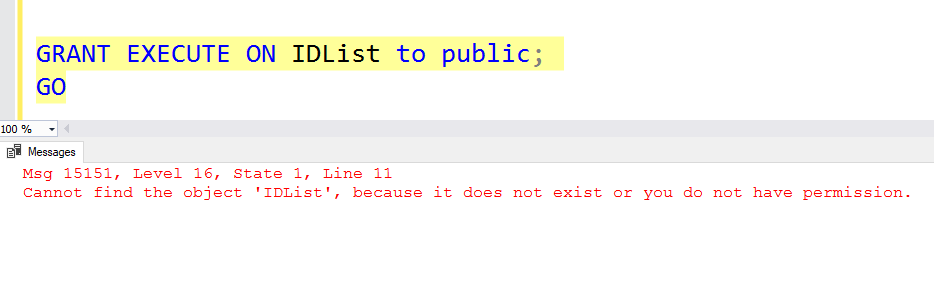
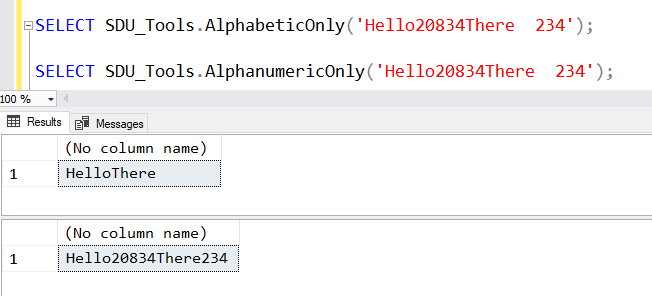
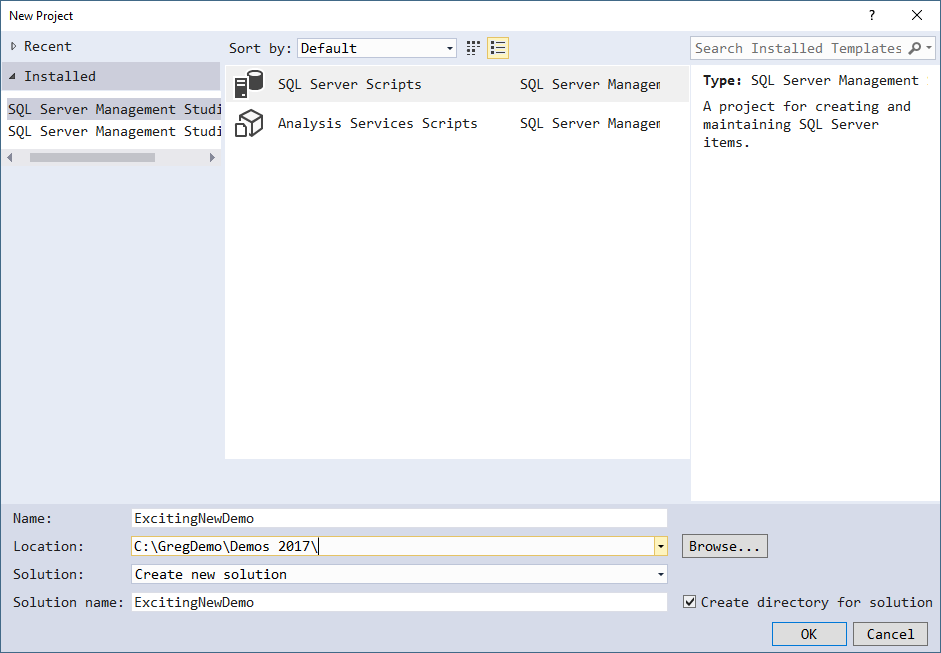
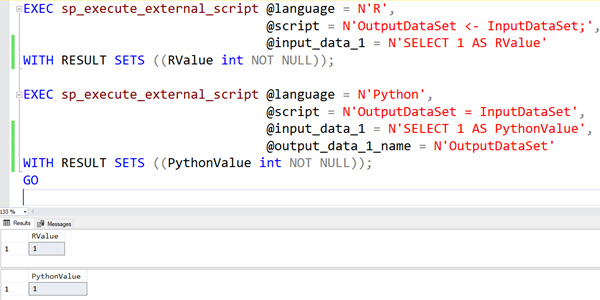
One of the wonderful additions to SQL Server in 2016 was the R language. In SQL Server 2017, Python was also added and the combination of both with SQL Server rebranded to Machine Learning Services.
Why would you want these installed? The most common answer is to enable you to run predictive analytics.
But I’ve found that at many sites, getting R and/or Python installed turned out to be more complicated than it seemed.
2018-05-16