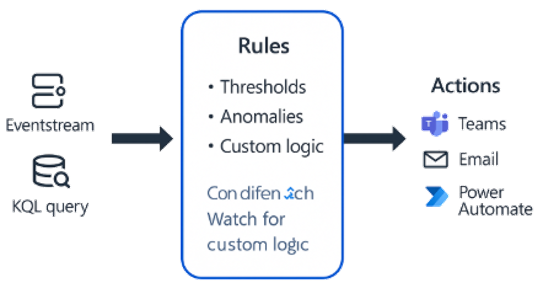
Fabric RTI 101: Integrating Logic Apps with Activator
Logic Apps are closely related to Power Automate, but they’re designed for enterprise IT teams that need more control, scalability, and governance.
Like Power Automate, Logic Apps let you automate workflows across systems using a visual, low-code designer.
However, Logic Apps are built on Azure, which gives them access to more advanced capabilities — such as higher throughput, better integration with on-premises systems, and enterprise-grade reliability.
You can think of Power Automate as being focused on business users and citizen developers, while Logic Apps are aimed at IT professionals and developers who build and maintain enterprise integrations.
2026-07-30