
Snowflake for SQL Server users - Part 3 - Core Architecture
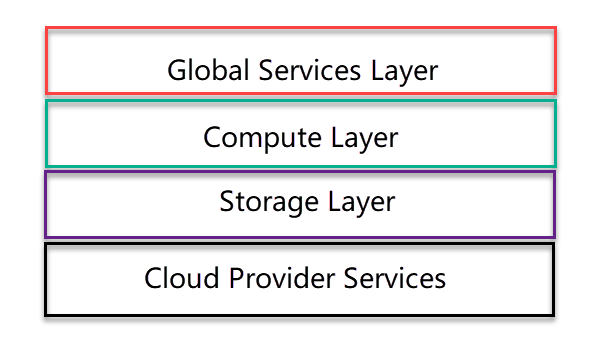
The first thing to understand about Snowflake is that it has a very layered approach. And the layers are quite independent, including how they scale.
Cloud Provider Services
The lowest level isn’t part of Snowflake; it’s the services that are provided by the underlying cloud provider. As a cloud native application, Snowflake is designed to use services from the cloud provider that they are deployed to, rather than providing all the services themselves. At present, that means AWS or Microsoft Azure. Deployment on Google’s cloud platform is in preview at this time.
Each deployment of Snowflake includes the upper three layers that I’ve shown in the main image above.
Storage Layer
This layer is exactly what it says. It uses storage from the cloud provider to provide a way to store anything that needs to be persisted. That includes, the obvious things like databases, schemas, tables, etc. but it also includes less obvious things like caches for the results of queries that have been executed.
Storage is priced separately from compute. While the prices differ across cloud providers and locations, the Snowflake people said they aren’t aiming to make a margin much on the storage costs. They’re pretty much passing on the cloud provider’s cost.
In addition, when you’re staging data (that I’ll discuss later), you can choose to use Snowflake managed storage or your own storage accounts with a cloud provider to hold that staged data.
Compute Layer
This is the heart of where Snowflake make their income. The compute layer is made up of a series of virtual clusters that provide the compute power to work on the data. Importantly, each of the virtual clusters (called Virtual Warehouses) can independently access the shared underlying storage.
Compute is charged by consuming what are called “credits”. I’ll write more about those soon. What is interesting is that you only pay for compute while a virtual warehouse is running.
While there are some blocking commands, the idea is that you should do most of those in staging areas, to keep your shared storage accessible in a highly concurrent way. The aim is to have a virtual warehouse happily querying the data, while another virtual warehouse is in the middle of bulk loading other data. And the virtual warehouses can each be different sizes.
Global Services Layer
This is the layer where all the metadata and control lives. It’s also where transactions are managed, and where security and data sharing details live. I’ll describe each of its functions in future posts.
For an index to all posts in this series, see the first post here.
2019-08-22