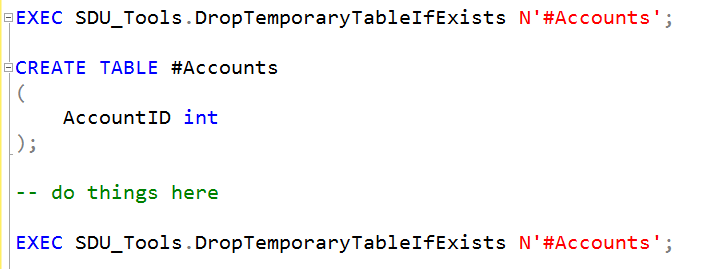
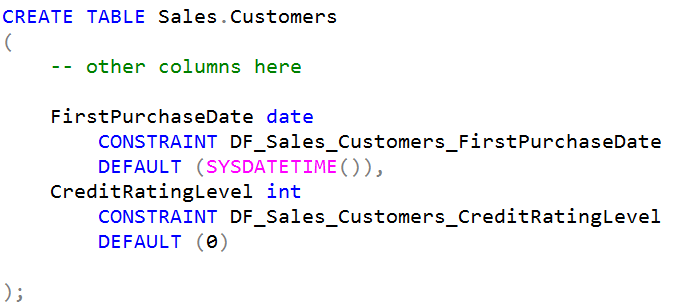
SDU Tools: ExecuteJobAndWaitForCompletion
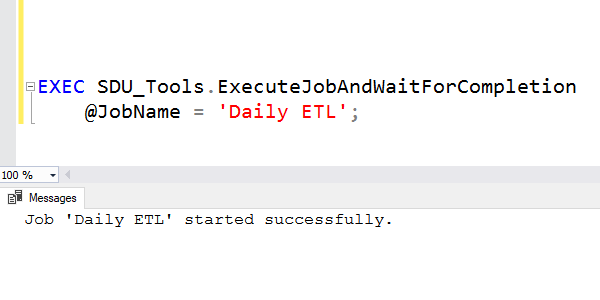
You can execute SQL Server Agent jobs from within T-SQL code. The procedure sp_start_job can do that.
That’s all well and good but notice that it doesn’t say “execute job”; it just says “start job”. The command starts the execution of a job but has no interest in when it completes.
Sometimes, you need to be able to start a job and wait for it to complete before taking a following action.
2018-08-01