
SQL: Even more details on finding rows that have changed using HASHBYTES and FOR JSON PATH
In a previous post, I wrote about how to create a hash of all the columns in a table, by using FOR JSON PATH and HASHBYTES. This is incredibly useful if you need to check if incoming data is different to existing table data.
The code that I suggested (based on WideWorldImporters) was as follows:
SELECT po.PurchaseOrderID,
HASHBYTES('SHA2_256', pod.PurchaseOrderData) AS HashedData
FROM Purchasing.PurchaseOrders AS po
CROSS APPLY
(
SELECT po.*
FOR JSON PATH, ROOT('Purchase Order'), INCLUDE_NULL_VALUES
) AS pod(PurchaseOrderData);
The challenge with that code though, is that for the existing table data, it’s best calculated when the data is stored, rather than every time it’s queried. And, bonus points if you then create an index that holds just the key for matching plus an included column for the HashedData. With a bit of careful work, you can get an efficient join happening to find differences.
The Challenge
The challenge with this, is that you might have a column in the data that should NOT be checked. Perhaps you’ve stored a column called HashedData in the table and it should not be included in the hash calculations. Or perhaps there’s an identity column that you really need to excluded.
The problem with the code above is that there wasn’t an easy way to exclude the column.
Making a Wish
What I really wish that SQL Server had is a way to exclude a specific column or columns from a SELECT list.
When you are writing utility code, it would be incredibly useful to be able to say just:
SELECT * EXCLUDE (ColumnIDontWant, AnotherColumnIDontWant)
FROM dbo.SomeTable;
I’m not a big Snowflake fan but it’s an example of something that it does better than SQL Server in T-SQL.
If I had that, I could have just excluded it in the CROSS APPLY above.
JSON_MODIFY to the Rescue
But there is a way around this. Since SQL Server 2016, we’ve had JSON_MODIFY.
And I can use that to modify the data before hashing it. So to exclude a column called HashValue, I can write:
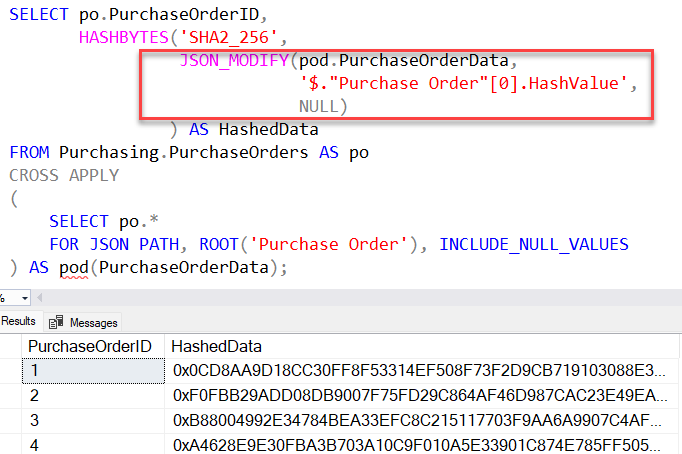
SELECT po.PurchaseOrderID,
HASHBYTES('SHA2_256',
JSON_MODIFY(pod.PurchaseOrderData,
'$."Purchase Order"[0].HashValue',
NULL)) AS HashedData
FROM Purchasing.PurchaseOrders AS po
CROSS APPLY
(
SELECT po.*
FOR JSON PATH, ROOT('Purchase Order'), INCLUDE_NULL_VALUES
) AS pod(PurchaseOrderData);
With JSON_MODIFY, we can choose a JSON property to remove by setting it to NULL.
This makes it far easier to write generic code, without the need to list all the columns (as you would with CONCAT or CONCAT_WS), and without the need for dynamic SQL.
2023-10-09