
SQL: Understanding Change Data Capture for Azure SQL Database - Part 2 - How does it work?

In the part 1 of this series, I discussed the positioning of Change Data Capture. In part 2, I want to cover how it works.
Log Reading
There are many ways that you can output details of changes that occur in data within SQL Server. Many of those methods require actions to occur at the time the data change is made. This can be problematic.
The first problem with this, is the performance impact on the application that’s making the change. If I update a row in a table and there is part of the process that writes details of that change to some type of audit or tracking log, I’ve now increased the work that needs to happen in the context of the application that’s making the change. Generally what this means, is that I’ve slowed the application down by at least doubling the work that needs to be performed. That might not be well-received.
The second potential problem is even nastier. What if the change tracking part of the work fails even though the original update works? If I’ve done the change tracking work in the context of the original update (particularly if it’s done as part of an atomic process), by adding tracking I might have broken the original application. That certainly wouldn’t be well-received.
So what to do?
The best answer seems to be to work with the transaction log that’s already built into SQL Server. By default, it does have details of the changes that have been occurring to the data. It can be read asynchronously so delays in reading it mostly won’t affect the original data changes at all (there are only rare exceptions to this). If the reading of the logs failed, the problem can be corrected and the reading can be restarted, all again without affecting the main updates that are occurring.
And that’s what Change Data Capture does. It uses the same log reader agent that has been part of SQL Server for a very long time. Previously though, it was used for Transactional Replication. In fact if you use both Transactional Replication and Change Data Capture on the same SQL Server system, they share the same instance of the log reader. The SQL Server Agent is used to make them both work.
SQL Server Agent - Isn’t that missing?
When we’re working with Azure SQL Database, things are a bit different. Currently, we don’t have any concept of Transactional Replication. That could change but right now, it’s not there. So sharing the log reader isn’t an issue.
But I also mentioned that with SQL Server, it was the SQL Server Agent that kicks off the log reading agent. And with Azure SQL Database, we don’t have SQL Server Agent either !
The Azure SQL Database team have instead provided a scheduler that runs the log reader (called the capture), and also runs the required clean-up tasks. SQL Server had another agent to perform clean-up. This is all automated and requires no maintenance from the user.
Change Data Capture (CDC) Data Flow
The data flow with CDC is basically like the following:
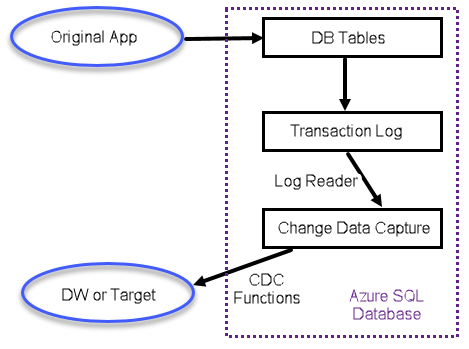
- The original app sends a change (insert, update, delete) to a table in the Azure SQL Database.
- The change is recorded in the transaction log.
- Some time later (usually not long though), the change is read by the capture process and stored in a change table.
- The Data Warehouse (DW) or target system or ETL system makes a call to a set of CDC functions to retrieve the changes.
Everything in the dotted box above is part of, and contained within, the Azure SQL Database.
Upcoming
In the next section, I’ll show you the code that’s required, and show you the changes that occur to the Azure SQL Database when you enable CDC.
- Why use Change Data Capture for Azure SQL Database?
- How Change Data Capture works in Azure SQL Database
- Enabling and using Change Data Capture in Azure SQL Database
- Change Data Capture and Azure SQL Database Service Level Objectives
- Accessing Change Data Capture Data from Another Azure SQL Database
2023-03-06