
T-SQL 101: 87 Summarise sections of data by using GROUP BY
When you calculate an aggregate, the default is that it applies to the entire table, but you might not want that.
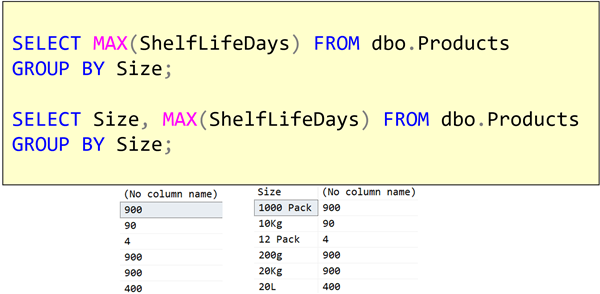
For example, I might want to calculate the longest shelf life for products. But I want to calculate that for each size of product.
If we look at the first example, we have added a GROUP BY clause to our query, and it returns exactly that. The output is on the left hand side below the query. For each size (determined by the GROUP BY), the maximum of the shelf life is returned.
But the problem is that even though it’s returning me the maximum shelf life days for each size, I have no idea which size corresponds to which answer that it returns.
Almost any time that you use a GROUP BY, while it’s not strictly required, you should include the columns that you are grouping by, in the SELECT clause. Then you can work out which answer is which.
The second query’s output is on the right-hand side. It’s much more useful.
Common Error
While this is all good, I also see people try and write a query like the second one here:

The first one is fine, but if I’m grouping by the Size, it makes no sense to try to SELECT the OuterQuantity.
The problem in the second query above is that you start by getting products, and grouping them by size. At that point, they’re not individual products, they’re rows that have the grouping columns and any aggregates. OuterQuantity isn’t part of that, so you can’t then SELECT it.
The basic rule is: you can only SELECT columns that are either:
- In the GROUP BY clause (and you should probably SELECT all of these)
- Columns that you have aggregated
- Constants (literal values that are unaffected by the grouping)
Learning T-SQL
It’s worth your while becoming proficient in SQL. If you’d like to learn a lot about T-SQL in a hurry, our Writing T-SQL Queries for SQL Server course is online, on-demand, and low cost.

2021-03-01