
T-SQL 101: 18 - Removing duplicate rows by using DISTINCT

If I query rows from a SQL Server table, I don’t always want all the rows returned. In particular, I might not want any duplicates. I can remove them by using DISTINCT.
Here’s a simple example. I want a list of the sizes that products can come in, so I execute this query:
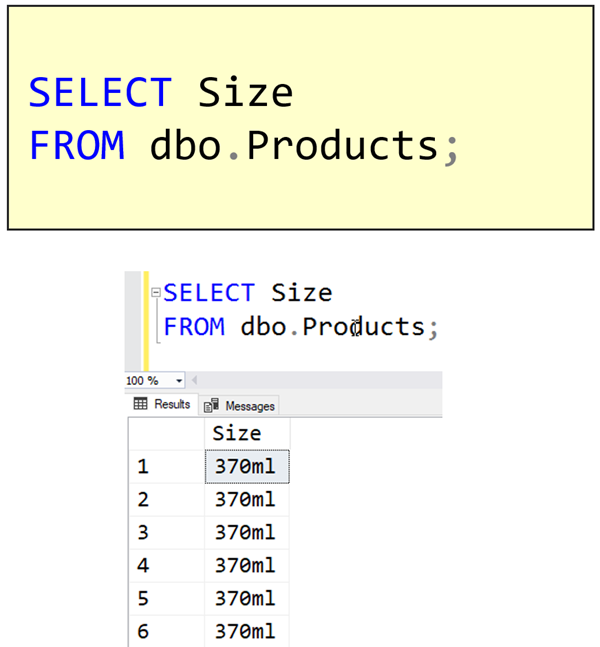
Note that although I get a list of sizes, I get a row returned for every row in the table. If I add DISTINCT to the query, look at the effect that it has:
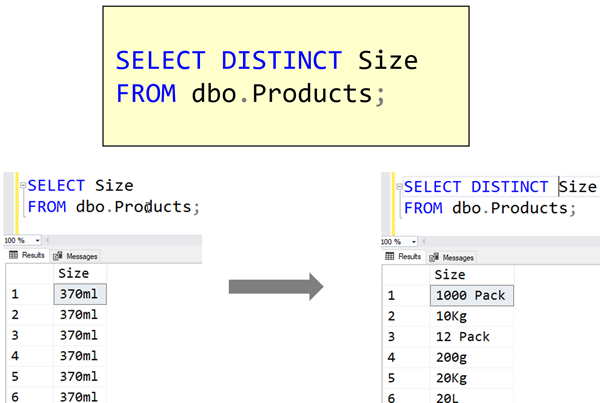
The removal of duplicates applies to all the columns listed after DISTINCT, so if I selected Size and Color, I’d get all the combinations of Size and Color that have been used.
The Perils of DISTINCT
I often run into situations where DISTINCT is overused. What happens is that developers don’t get their join operations working properly, end up with duplicates, and “fix” the query by adding DISTINCT to the SELECT clause at the top. Try to avoid this by making sure your joins are done properly first. Don’t rely on DISTINCT to fix join problems.
DISTINCT vs GROUP BY
In a later post, we’ll talk about GROUP BY but it’s worth noting that writing:
SELECT DISTINCT Size FROM dbo.Products ORDER BY Size;
is really the same as writing:
SELECT Size FROM dbo.Products GROUP BY Size ORDER BY Size;
Learning T-SQL
It’s worth your while becoming proficient in SQL. If you’d like to learn a lot about T-SQL in a hurry, our Writing T-SQL Queries for SQL Server course is online, on-demand, and low cost.

2019-05-20