
SQL: What's in a (default) name?
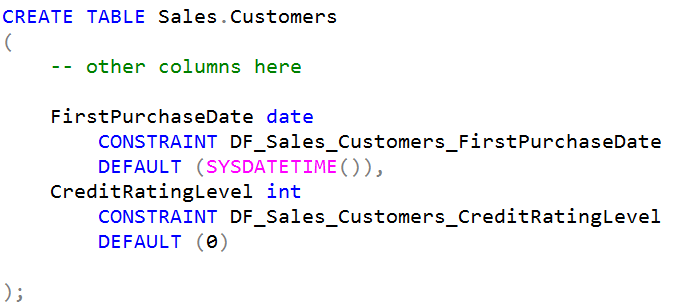
I often see people creating databases in SQL Server and not specifying the name of defaults they are applying to columns. They define a column like this:

And there are general reasons why this makes sense. For example, a column can only have one default, so what does the name matter anyway?
There are two reasons:
Dropping columns
In SQL Server, you’ll find that if you go to drop either of those columns, you’ll see something like this:
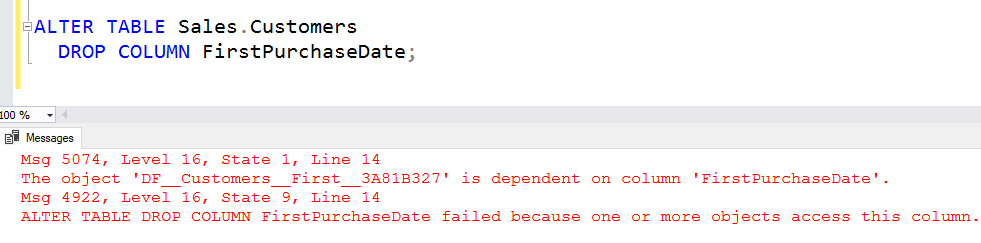
SQL Server requires you to drop the default constraint on the column before you can drop the column, and unfortunately it requires you to do that by name. Notice the name that it chose for the default: DF__Customers__First__3A81B327. Life is far, far easier if you have a pattern that means you already know the name that will have been applied.
DevOps and Database Comparisons
As part of DevOps or other techniques, you’ll end up wanting to compare two databases to find what’s different. While some tools help with this, having the same table definition create defaults with different names isn’t going to be helpful in this.
Naming
It doesn’t matter too much what pattern you use for the names. I’d use this one:

I use the schema name, the table name, and the column name. That can’t go wrong or end in duplicates. And I already know the names of my defaults, and they’re easy to generate programmatically.
Alternatives
Keep in mind that this is a SQL Server specific thing. In other languages like PostgreSQL, you can’t apply a name to a default constraint. But you don’t need to because column defaults are automatically dropped when the column is. (No idea why SQL Server doesn’t just do this). And you can drop a default with the DROP DEFAULT clause to ALTER TABLE without needing a name for the default.
These are things that SQL Server should copy but until they do, name your default constraints.
2018-07-23