
SQL: Finding rows that have changed in T-SQL - CHECKSUM, BINARY_CHECKSUM, HASHBYTES

If you have data in a SQL Server table and you want to know if any of the values in a row have changed, the best way to do that is by using the rowversion data type. (Note: this used to be called the timestamp data type in a rather unfortunate naming choice). I’ll talk more about it in another post.
But today I wanted to discuss the another issue. If I have an incoming row of data (let’s say @Parameter1, @Parameter2, @Parameter3, @Parameter4) and I want to know if the incoming values match the ones already in the table and update the table only if they are different, what’s the best way to do that/
You might think that’s easy and you’d just add a WHERE clause to your UPDATE like:

If you have a large number of columns, doing that gets old pretty fast. Worse, if the columns are nullable, it really needs to be more like this:
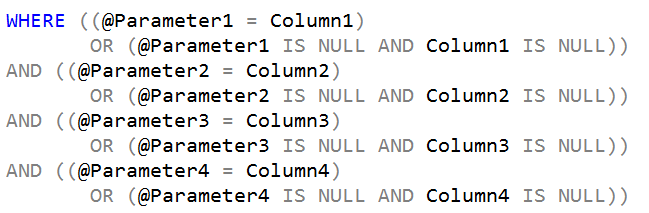
You can imagine what this looks like if there are a large number of columns, and you can imagine the amount of calculation that could be needed, just to see if one value has changed.
An alternative approach is to add one more column that represents a checksum or hash value for all the columns, and to just compare that.
The first challenge is to get a single value. Fortunately, the CONCAT function provided in SQL Server 2012 and later works a treat. It promotes all values passed to it to strings, ignores NULL values, and outputs a single string. This means we could calculate the hash or checksum like this:

and we could then compare that to the precomputed value we stored when we last inserted or updated the row. (Either directly inserting the value or via a persisted computed column)
It might be worth using an alternate separator if there’s any chance it could occur at the end of any value.
If you are using SQL Server 2017 or later, you’d hope that you could use the CONCAT_WS (concatenate with separator) function instead but unfortunately, it ignores NULL values, so you’d have to wrap them all with ISNULL or COALESCE.

It would have been great if that function had a way to not ignore NULL values, or to have another function provided. It would be really useful if you wanted to generate output lines for CSV or TSV files.
The question that remains is about which hashing function to use.
I often see customers trying to use the CHECKSUM function for this. The problem with CHECKSUM is that it returns an int and you have a reasonable chance of getting a collision. That would be bad, as you’d assume that data was the same when it wasn’t. A while back, we got the documentation people to write specific notes about this. You’ll notice the web page now says:
“If at least one of the values in the expression list changes, the list checksum will probably change. However, this is not guaranteed.”
I’m assuming you want something better than that.
BINARY_CHECKSUM sounds better but it’s really more like a case-sensitive version of CHECKSUM, and unless you’re working with case-sensitive servers, that’s even worse.
The real answer is a true hashing function, and in SQL Server that means HASHBYTES. It’s computationally more intensive but is suitable for this type of change detection. The hassle with it was that it was limited to 8000 bytes. Fortunately, in SQL Server 2016 and later, that limitation was removed, so it’s now the one to use:

The other point made by our buddy Ron Dunn in the comments is extremely valuable. If you are using CONCAT to combine numbers and date/time values, it’s critical that you always format them as strings yourself to control the format used. That way, you won’t fall foul of different regional or language settings.
2018-07-02