
Opinion: When does NULL make sense for database columns

One thing that seems to get developers hot under the collar is whether their database columns should be nullable or not.
As mentioned in earlier posts, some try to just have everything NOT NULL to avoid dealing with the issue. But that can lead to the use of magic values where you store a value that means “there is no value” just to avoid the value being NULL. The problem with magic values is that every layer of code needs to know what’s happening. These values inevitably leak into the outside world.
In the example below, I’m guessing the date for the last update really was meant to mean “Never”.
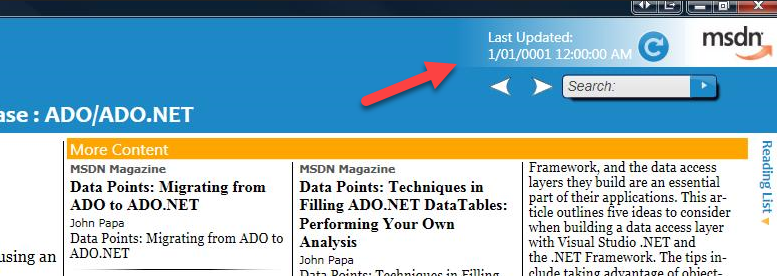
I’d also guess that the wind speed of 999 here means “we don’t have a value”:
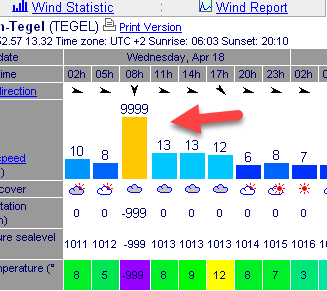
(The precipitation value under it of -999 also sounds pretty dry)
So the question is still about which sorts of values should be NULL.
First, having a NULL value is completely different to a value being zero, or being a zero-length string. There’s a difference between not knowing a temperature, and knowing that the temperature is zero.
In the pubs database that shipped as the first SQL Server sample, there was a nullable column called ytd_sales. I always thought that it was a great example of a column that shouldn’t be nullable. If there aren’t any sales for the year, ytd_sales is zero, not NULL (unknown).
A more suitable candidate would be LastSaleDate for a customer. If you haven’t ever had any sales, there is no sensible value that you can put into that column to avoid it being NULL. Anything else immediately becomes a magic value.
My purist friends though, would argue that the problem with LastSaleDate is that you shouldn’t be storing it in the database in the first place. Instead, you should simply be storing each sale and when it occurred. The LastSaleDate would then be derived from the lack of sale rows rather than from a column.
NULL columns should be those where it makes sense to not have data and for the row to still be valid.
2018-06-05