
SDU Tools: Read CSV File in T-SQL

One of the most common tasks that “data people” perform is moving data around, and that can include exporting existing database data, and importing data from other places.
While there are many other standards for how data is stored in files, CSV (comma-separated-value) files are still (by far) the most common. Another common variation are TSV (tab-separated-value) files, where tabs are used to separate values instead of commas. This is usually a good idea as commas occur frequently within the data.
Given these file formats are so common, how easy it is to read these files using T-SQL? And the answer is “way more complicated than it should be”.
So, we built one of our SDU Tools to come to the rescue. Our ReadCSV stored procedure takes the following parameters:
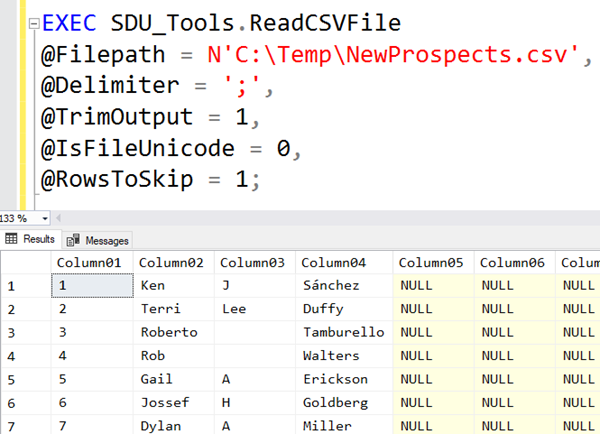
@Filepath nvarchar(max) - this is the full path to the CSV or TSV file @Delimiter nvarchar(1) - delimiter used (default is comma but can be another character like tab) @TrimOutput bit - should all output values be trimmed before returned (very handy) @IsFileUnicode bit - 1 if the file is unicode, 0 for ASCII @RowsToSkip int - should rows be skipped (eg: 1 for a single header row with column names if it is present)
Here’s is an example of it being called:
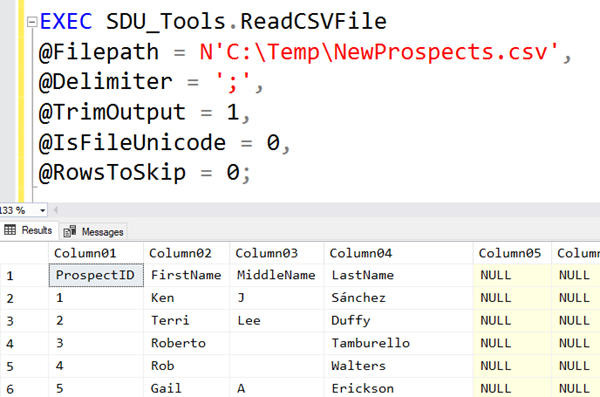
The procedure returns 50 columns named Column01, Column02, and so on. It always returns 50 columns and will return NULL for any missing values. Note in this example though, that the column names were in the first row. So we can fix that by skipping the first row as shown in the main image above:
You can see the tool in action here:

For more information on our free SDU Tools and to join our SDU Insiders to get more information on our tools, eBooks, webinars, etc. please just visit here:
https://sqldownunder.com/freestuff
2018-05-18