
SQL: Why ANSI_NULLS matters for SQL Server Tables
Recently, I posted a link to show how to turn on ANSI_NULLS for a table. It’s not normally easy to change that but we added a procedure to our free SDU Tools to make it easy.
But one of the comments I received was a question basically saying “OK, you’ve shown how to change it but you haven’t mentioned why it matters in the first place”.
Fair enough. So that’s the topic of today’s post.
Many developers (and database people) get confused about the handling of NULL values. When we talk about a value being NULL, what we’re really saying is that it has no value. This is quite different to a number being zero, or a string being empty (or zero-length).
It’s also why we can’t compare a value to NULL by using an equals sign (or not equals), but by saying IS NULL or IS NOT NULL instead. Being NULL is a state that a variable or column is in, not a value that it holds.
It’s worth noting that some database engines still don’t even get this right. And SQL Server was one of those in its past.
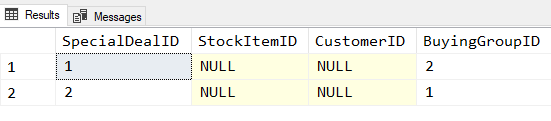
Here’s an example. In the WideWorldImporters database, there is a Sales.SpecialDeals table. It has many columns but when it was shipped, it had two rows. Let’s look at those.
Note that if I try to select the rows where StockItemID = NULL, I get no rows but if I compare where StockItemID IS NULL, I get the rows.
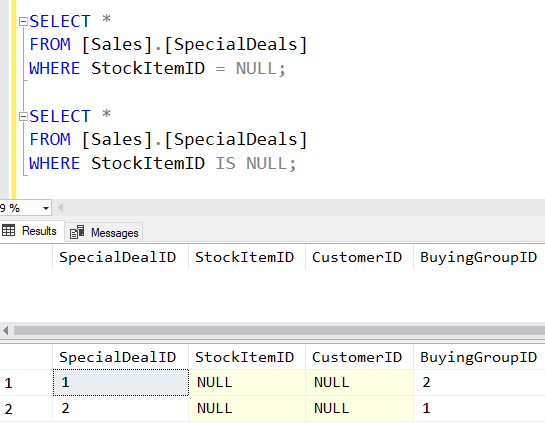
This is because a WHERE clause returns rows where the value of the predicate is TRUE. But with ANSI_NULLS on, NULL does not equal NULL. A comparison of NULL and NULL returns NULL.
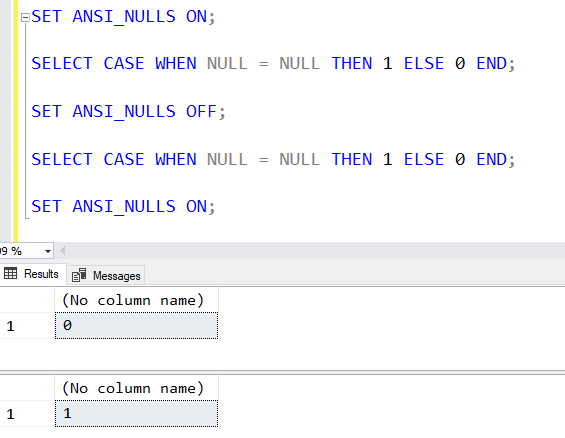
You can see how the comparison works with and without ANSI_NULLS ON here:
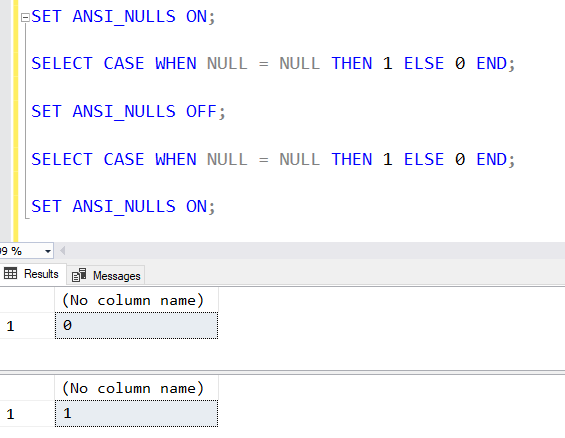
SET ANSI_NULLS OFF takes us back to the bad old days whereas SET ANSI_NULLS ON gives us ANSI standard SQL behavior on this. We don’t want our tables declared with ANSI_NULLS OFF. (Or worse, I’ve seen some tables declared that way and others not).
You can read more here:
https://docs.microsoft.com/en-us/sql/t-sql/statements/set-ansi-nulls-transact-sql
2018-03-19