
SQL: Design - Entity Attribute Value Tables (Part 1) - Why?

If you’ve been working with databases for any length of time, you will have come across implementations of Entity-Attribute-Value (EAV) data models (or non-models as some of my friends would call them).
Instead of storing details of an entity as a standard relational table, rows are stored for each attribute.
For example, let’s create a table of people:
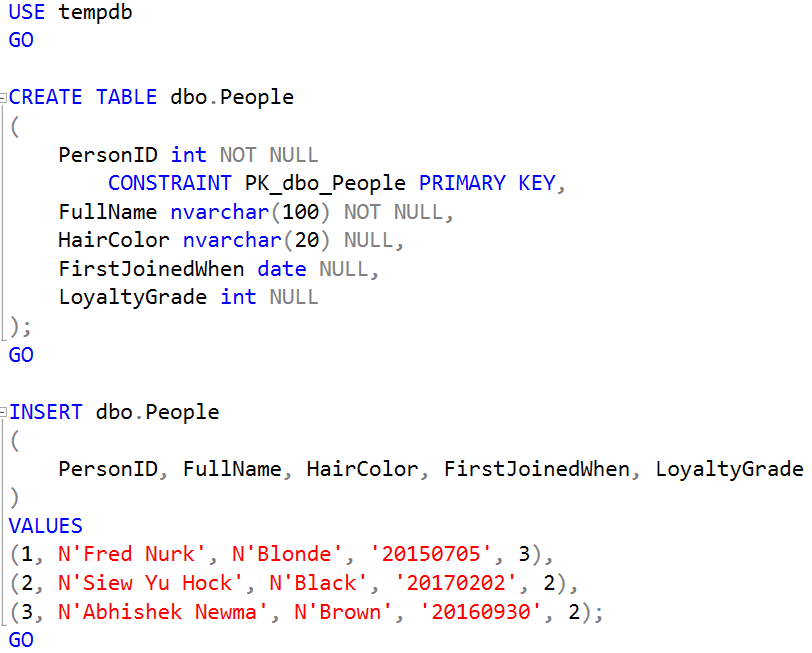
When we query it, all is as expected:
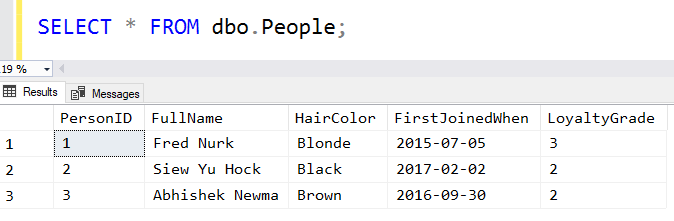
And for a long time, this has been how we expect to create tables.
Now, if we changed the previous code to be EAV based, we could do this:
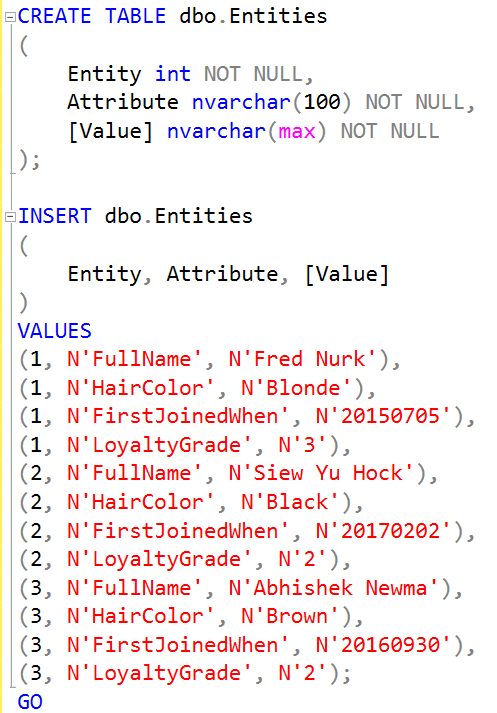
And when we query it, we’d see this:
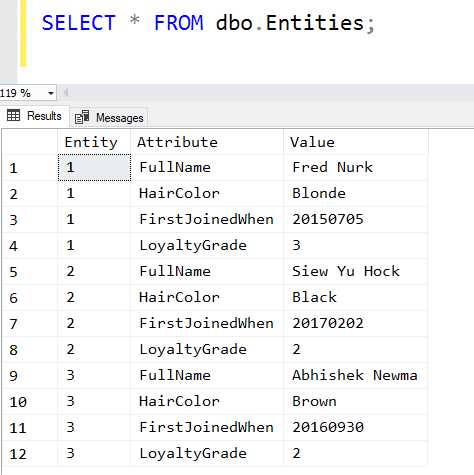
Clearly this is going to be much harder to work with for all operations apart from reading and writing a list of values by the entity’s ID.
So the first question that arises is:
Why would anyone want to have this sort of (non) design in the first place?
There are a few reasons. Some ok, some not ok.
Reason 1: Sparse Data
EAV tables first appeared for situations where there was a large number of potential attributes (ie: columns here) and each entity (ie: row here) only had a few of them. You can see a description of this in Wikipedia here: https://en.wikipedia.org/wiki/Entity%E2%80%93attribute%E2%80%93value_model
Products like SharePoint had this issue, and that’s what pushed the SQL Server team to vastly increase the number of columns per table in SQL Server 2008. Prior to that version, you could have 1024 columns per table, and most people would have considered that if you needed more than that, you were doing something wrong. SQL Server 2008 increased the number of columns per table to 30,000, and also added the concept of a SPARSE column. Unlike standard columns that would always have occupied at least one bit in a NULL bitmap, SPARSE columns only occupy space when they contain data.
To avoid issues with indexes on the sparse columns, we also got filtered indexes in that version. They were highly useful for many reasons, not just for sparse columns.
The addition of SPARSE columns allowed SQL Server to use relational tables to get around the reasons that were the basis for the requirement for EAV tables.
Reason 2: Flexibility?
If we assume that we’re not working with a sparse design, what’s next? I often hear this type of design referred to as “flexible”. When I quiz developers on what they mean by that, it basically boils down to:
I don’t have to change the database schema when I add or remove attributes, or even tables.
So they have basically created a table to rule them all.
This simply isn’t a good reason. It might stem from either working in organizations where someone else controls the database and they’re difficult to work with, or don’t want to make changes quickly enough. But that’s fixing the wrong problem. It can also stem from a basic lack of design in the first place.
Reason 3: Object Repository
We only want to use the database as an object repository. All logic occurs outside the database. We just want to serialize objects in and out of the database. If you have this reason, I love you. You keep me in work, dealing with organizations with intractable performance issues. Fine for a toy application, not fine for an enterprise application.
Worse, this type of design tends to lead to information silos where the data storage is specific to the one version of one application. That’s not what enterprises need. They typically have many applications that use the same data, and those applications are built on more than one technology stack.
More to Come
Now there are other reasons and I’ll discuss them in the next article on this topic, when we discuss the pros and cons of this type of design, but I wanted to start with the definitions and the basic “why” question.
If you have other “why” options, please let me know in the comments.
2018-02-12