
SDU Tools: List Subset Indexes

Everyone working with databases knows that having too many indexes can be a problem. Indexes need to be modified whenever the data in the associated tables need to be modified, so yes it can slow down data inserts, updates, and deletes.
How big a problem is too many indexes?
Overall, I’m not as concerned about this as many other people seem to be. I always want to focus on what the system is spending its time doing, and on most systems that I work on, that’s reading, not writing.
Any time I ask someone what percentage of the time does their system spend writing, they always tell me numbers like 10% or 20% or 30%. I even recently had discussions with a SQL product group member who told me that he thought 40% to 60% was common. I just don’t believe any of these numbers, or at least not for OLTP systems. Every time I measure it, the outcome is closer to 1%, or perhaps 2%. So while I acknowledge that there are systems where that 1% of the effort is time-critical, I usually get much better outcomes from optimizing the 99% of the workload, not the 1%.
And if you optimize the 99%, no surprise that the 1% benefits as well.
Finding data to modify is important too
It’s also important to keep in mind that to modify data, you need to find it first. Yes, I understand that if all you ever do is to access rows one at a time by their primary key (a big shout-out hello to all the ORM fans), that’s not an issue. But if you have an address table and want to correct the name of a city in every row, you’ll sure be glad you had an index to let you find those rows quickly. Even most systems that modify data heavily spend a bunch of time reading, not writing.
Pointless Indexes
So, while we’re acknowledging that the indexing issue often isn’t as bad as made out, it’s pointless having indexes that aren’t being used. They are just unnecessary overhead.
I’ll talk about many of these in other blog posts but there are two categories of index that I need to call out specifically.
Single column nonclustered indexes - these are so often pointless. Unless they end up being super-selective in your queries (and I’m talking way less than even 1% selectivity), you’ll find that SQL Server will quickly end up ignoring them, as the cost of the associated lookups is too high. That’s a topic for another day.
Subset indexes - these are the ones I want to highlight today. If I have an index on Columns A, B, and C and another index on Columns A and B, it’s very, very likely that you could live without the subset index on Columns A and B only. Clearly other things like included columns need to be considered but as a general rule, these are indexes that come into the “code smell” territory.

So I have a tool for that. One useful proc in the SDU Tools collection is ListSubsetIndexes.
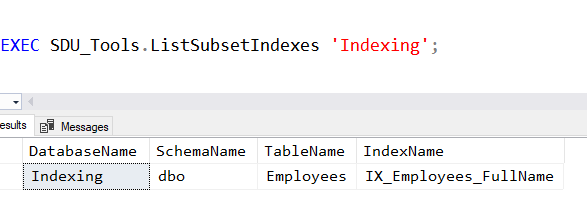
It takes a single parameter, either the name of a database, or a comma-delimited list of databases to check. If you omit the parameter or provide the value ALL, then all user databases on the server are checked.
You can see it in action here:

You can find out more about our free SDU Tools here:
https://sqldownunder.com/freestuff
2017-11-24