
Naming CHECK and UNIQUE Constraints
I’m not a fan of letting the system automatically name constraints, so that always leads me to thinking about what names I really want to use. System-generated names aren’t very helpful.
Primary keys are easy. There is a pretty much unwritten rule that SQL Server people mostly name them after the table name. For example, if we say:
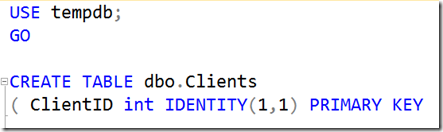
A violation of the constraint will return a message like:

The name isn’t helpful and it shows us the key value but not which column was involved.
So, we might say:
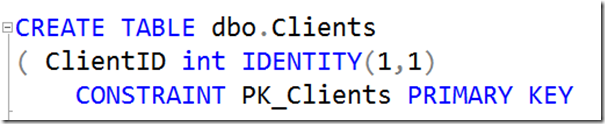
Even in this case, there are a few questions:
- Should the name include the schema? (ie: PK_dbo_Clients) If not, this scheme has an issue if there are two or more tables in different schemas with the same table name.
- Should the name include the columns that make up the key? (ie: PK_dbo_Clients_ClientID) This might be useful when an error message is returned. A message that says that you violated the primary key, doesn’t tell you which column (or columns) were involved.
So perhaps we’re better off with:

I do like to name DEFAULT constraints in a similar consistent way. In theory it doesn’t matter what you call the constraint however, if I want to drop a column, I first have to drop the constraint. That’s much easier if I have consistently named them. I don’t then have to write a query to find the constraint name before I drop it. I include the schema, table, and column names in the DEFAULT constraint as it must be unique within the database anyway:

CHECK constraints (and UNIQUE constraints) are more interesting. Consider the following constraint:
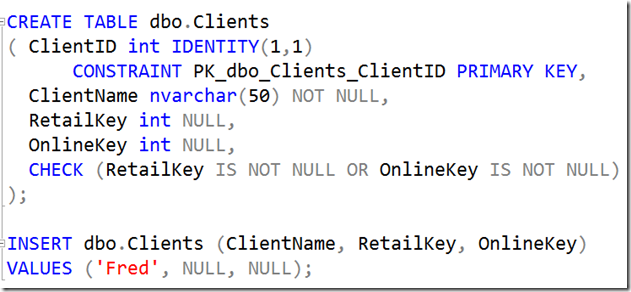
The error returned is:

Note how (relatively) useless this is for the user. We could have named the constraint like so:
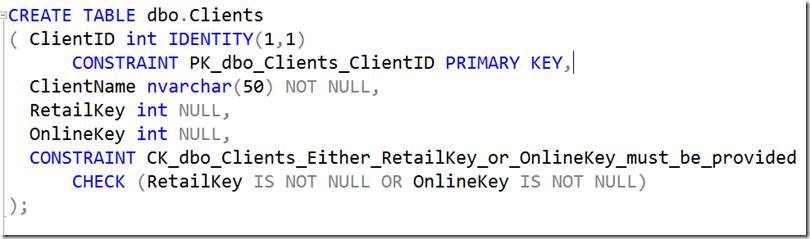
Note how much more useful the error becomes:

And if we are very keen, we might remove the underscores and delimit the name to make it more readable:

This would return:

I’d like to hear your thoughts on this. How do you name your constraints?
2014-11-12