SSMS Tips and Tricks 3-11: Using bookmarks
In a previous post, I was discussing how outlining can be helpful with navigating around within a large T-SQL script file.
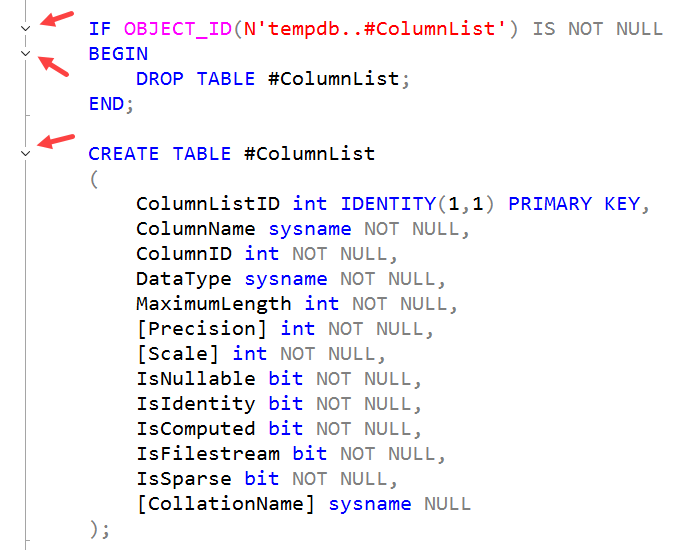
If you were trying to do that within a Microsoft Word document, the most common thing to use is bookmarks, and SQL Server Management Studio (SSMS) has them as well.
Bookmarks are simply placeholders within a script. (They can also apply to other types of document within SSMS). Where I find them very useful is when I’m working in two or three places within a long script at the same time. Perhaps I’m working on a function, and also on the code that calls the function. By using bookmarks, I’m not flipping endlessly around the script file, and can jump directly from placeholder to placeholder.
2025-07-18